About SciCode
The SciCode benchmark is a scientist-curated benchmark for scientific programming tasks utilizing Python. 65 main problems are provided with gold-standard solutions covering Chemistry, Materials Science, Biology, Math, and Physics. Each main problem is further divided into sub-problems, all of which must be solved correctly to achieve the main result. A dataset is included for verifying calculations.
We run this benchmark with “background” enabled, meaning the model is given a detailed description of the mathematics and theory for the problem to be solved. Enabling background is not the “standard setup” (per the cited paper), however this choice gives small models a better chance to compete by shifting the emphasis from general knowledge of scientific concepts toward scientific instruction following.
Results
Note: These findings are based on internal research and do not constitute an endorsement of any model for any specific purpose. This list will be updated frequently - please check back here for updates.
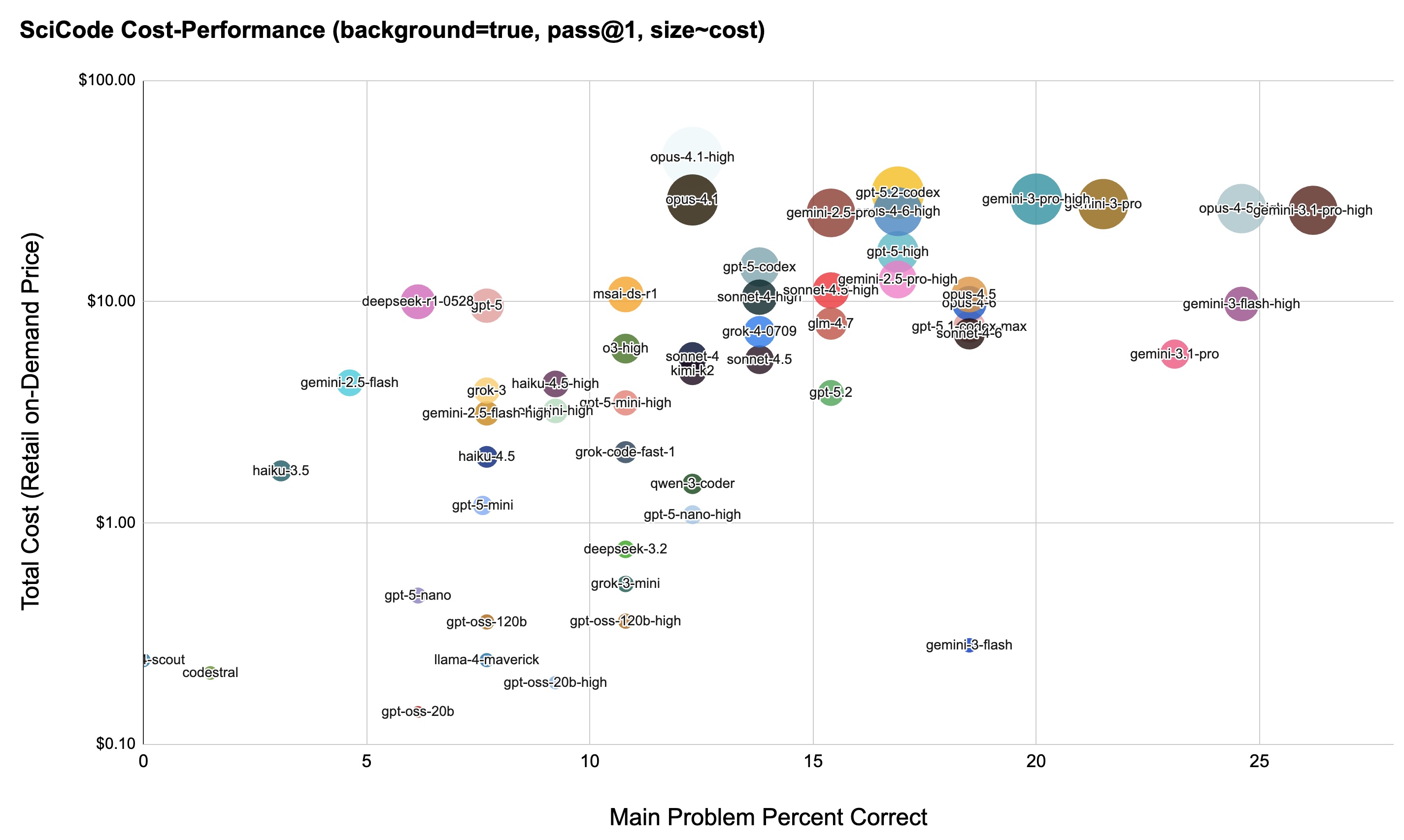
| Model | % Correct | Cost | Note | Config | Date |
|---|---|---|---|---|---|
| gemini-3.1-pro-high | 26.2% | $25.90 | ✅ | Gemini 3.1 Pro Preview reasoning_effort=“high” | 2026-02-22 |
| gemini-3-flash-high | 24.6% | $9.77 | ✅ | Gemini 3 Flash reasoning_effort=“high” | 2026-01-23 |
| claude-opus-4-5-high | 24.6% | $26.37 | Opus 4.5 reasoning_effort=“high” | 2025-12-02 | |
| claude-opus-4-5-high | 24.6% | $26.37 | Opus 4.5 reasoning_effort=“high” | 2025-12-02 | |
| gemini-3.1-pro | 23.1% | $5.80 | Gemini 3.1 Pro Preview | 2025-02-22 | |
| gemini-3.0-pro | 21.5% | $27.63 | Gemini 3.0 Pro Preview | 2025-12-02 | |
| opus-4-6 | 18.5% | $9.84 | Opus 4.5 | 2026-02-22 | |
| gemini-3-flash | 18.5% | $0.28 | ✅ | Gemini 3 Flash | 2026-01-23 |
| gpt-5-1-codex-max | 18.5% | $7.72 | OpenAI gpt-5-1-codex-max | 2026-01-23 | |
| claude-opus-4-5 | 18.5% | $10.78 | Opus 4.5 | 2025-12-02 | |
| gemini-2.5-pro-high | 16.9% | $12.60 | Gemini 2.5 Pro reasoning_effort=“high” | 2025-08-22 | |
| opus-4-6-high | 16.9% | $25.53 | Opus 4.6 reasoning_effort=“high” | 2025-02-22 | |
| gpt-5-high | 16.9% | $16.80 | OpenAI gpt-5 reasoning_effort=“high” | 2025-09-26 | |
| gpt-5.2 | 15.4% | $3.87 | OpenAI GPT 5.2 | 2026-01-23 | |
| glm-4.7 | 15.4% | $7.97 | ⚠️ | GLM 4.7 on GCP Vertex AI | 2026-01-23 |
| claude-sonnet-4-5-high | 15.4% | $11.25 | Sonnet 4.5 reasoning_budget=8192 | 2025-09-30 | |
| claude-sonnet-4-5 | 13.8% | $5.47 | Sonnet 4.5 | 2025-09-30 | |
| gpt-5-codex | 13.8% | $14.35 | OpenAI gpt-5-codex | 2025-09-26 | |
| claude-sonnet-4-high | 13.8% | $10.49 | Sonnet 4.0 reasoning_budget=8192 | 2025-08-22 | |
| gemini-2.5-pro | 13.8% | $25.33 | Gemini 2.5 Pro | 2025-08-22 | |
| gpt-5-1-codex | 13.8% | >$40 | 😢 | OpenAI gpt-5-1-codex (unable to complete) | 2025-12-02 |
| grok-4-0709 | 13.8% | $7.13 | 😢 | xAI Grok 4 0709 (unable to complete) | 2025-08-24 |
| gpt-5-nano-high | 12.3% | $1.09 | OpenAI gpt-5-nano reasoning_effort=“high” | 2025-09-26 | |
| qwen-3-coder | 12.3% | $1.50 | ⚠️ | qwen3-coder-480b-a35b-instruct | 2025-08-22 |
| kimi-k2-thinking | 12.3% | $4.85 | ⚠️ | qwen3-coder-480b-a35b-instruct | 2025-08-22 |
| claude-sonnet-4 | 12.3% | $5.32 | Sonnet 4.0 reasoning=false | 2025-08-22 | |
| claude-opus-4-1 | 12.3% | $28.85 | Opus 4.1 reasoning=false | 2025-08-22 | |
| claude-opus-4-1-high | 12.3% | $45.00 | ⛔ | Opus 4.1 reasoning_budget=8192 | 2025-08-22 |
| deepseek-3.2 | 10.8% | $0.76 | ⚠️ | Deepseek 3.2 on GCP Vertex AI | 2026-01-23 |
| gpt-oss-120b-high | 10.8% | $0.36 | gpt-oss-120b reasoning_effort=“high” | 2025-08-24 | |
| mistral-large-3 | 10.8% | $0.56 | MistralAI Large 3 | 2026-02-23 | |
| grok-3-mini | 10.8% | $0.94 | xAI Grok 3 Mini | 2025-08-29 | |
| grok-code-fast-1 | 10.8% | $2.09 | xAI Code Fast 1 | 2025-08-29 | |
| gpt-5-mini-high | 10.8% | $3.49 | OpenAI gpt-5-mini reasoning_effort=“high” | 2025-09-26 | |
| o3-high | 10.8% | $6.14 | OpenAI o3 reasoning_effort=“high” | 2025-08-22 | |
| gpt-oss-20b-high | 9.3% | $0.19 | ✅ | gpt-oss-20b reasoning_effort=“high” | 2025-08-24 |
| o4-mini | 9.3% | $3.21 | OpenAI o4-mini reasoning_effort=“high” | 2025-08-22 | |
| haiku-4-5-high | 9.3% | $4.25 | Anthropic Haiku 4.5 reasoning_effort=“high” | 2025-10-17 | |
| gpt-oss-20b | 6.1% | $0.14 | ✅ | gpt-oss-20b | 2025-08-22 |
| llama-4-maverick | 7.6% | $0.24 | Vertex AI Llama 4 Maverick | 2025-08-24 | |
| gpt-oss-120b | 7.6% | $0.35 | gpt-oss-120b | 2025-08-22 | |
| gpt-5-mini | 7.6% | $1.20 | OpenAI gpt-5-mini | 2025-08-22 | |
| haiku-4-5 | 7.6% | $1.99 | Anthropic Haiku 4.5 | 2025-10-17 | |
| gemini-2.5-flash-high | 7.6% | $3.12 | Gemini 2.5 Flash reasoning_effort=“high” | 2025-08-22 | |
| grok-3 | 7.6% | $3.96 | xAI Grok 3 | 2025-08-23 | |
| gpt-5 | 7.6% | $9.60 | OpenAI gpt-5 non-reasoning | 2025-08-22 | |
| gpt-5-nano | 6.1% | $0.47 | OpenAI gpt-5-nano | 2025-08-22 | |
| deepseek-r1-0528 | 6.1% | $10.00 | ⛔ ⚠️ | DeepSeek R1-0528 on GCP Vertex AI | 2025-08-23 |
| haiku-3-5 | 3% | $1.72 | ⛔ | Claude 3.5 Haiku | 2025-08-22 |
| codestral | 1.5% | $0.21 | Mistral AI Codestral | 2025-08-22 | |
| llama-4-scout | 0.0% | $0.24 | ⛔ | Vertex AI Llama 4 Scout | 2025-08-22 |
Discontinued Models
| Model | % Correct | Cost | Note | Config | Date |
|---|---|---|---|---|---|
| azure/deepseek-r1 | 10.8% | $10.00 | ⛔ ⚠️ | Azure Foundry MSAI-DS-R1 | 2025-08-23 |
Explanation of Notes
✅: Pareto-frontier optimal model (best cost-performance ratio in its performance tier - green dashed line in plot).
⛔: Unusually expensive for performance tier. Consider alternatives.
😢: Model was unable to complete benchmark (e.g. infinite loop in reasoning stage). Results are estimated.
⚠️: May contain censorship and/or has weak gaurdrails compared to alternatives. Use with caution.
Current CBorg Model Mappings
lbl/cborg-coder: gpt-oss-120b-high
lbl/cborg-deepthought: gpt-oss-120b-high
lbl/cborg-mini: gpt-oss-20b-high
lbl/cborg-chat: llama-4-scout
Changelog
Dec 2nd, 2025
- Added results for Claude Opus 4.5 and Gemini 3.0 Pro Preview
Sept 30th, 2025
- Added results for Claude Sonnet 4.5 standard and reasoning_effort=high
- Updated green checkmarks to indicate Pareto-frontier models only
Sept 26th, 2025
- Added results for gpt-5 variants with reasoning_effort=“high” configuration
- gpt-5-high tied with gemini-2.5-pro-high for highest score
- Added gpt-5-codex result
Aug 29th, 2025
- Re-calculated Grok 3 Mini costs based on xAI API costs (approx 50% cheaper than Azure Foundry costs)
- Added results for new Grok Code Fast 1 model
Aug 24, 2025
- Corrected error in gpt-oss benchmarks with -high setting and updated scores
- Added xAI Grok 4 0709 - Model was unable to complete 4 problem sets after 2 hours of retries.
- Added Meta Llama 4 models.
Aug 23, 2025
- Added Azure MSAI-DS-R1 (DeepSeek R1 post-trained by Microsoft AI)
- R-ran Qwen 3 Coder benchmark to verify cost (no change)
- Added xAI Grok 3. Grok 3 Mini was unable to complete benchmark - will try again
- Added DeepSeek R1 0528 from Vertex AI